
London Marathon App Crash
The Daily Mirror reported the crash of the London Marathon App early into yesterday's race.
The app is used by runners and their friends and family to deliver three functions:
- View the leader-board of the top 20 or so elite athletes in near real time
- View the times/position of any runner on a map, updated every 5km
- View the results at the end of the race
38,000 runners took part in the event. Around 11am, 1 hour into the race, users were greeted with the following error when accessing the app:
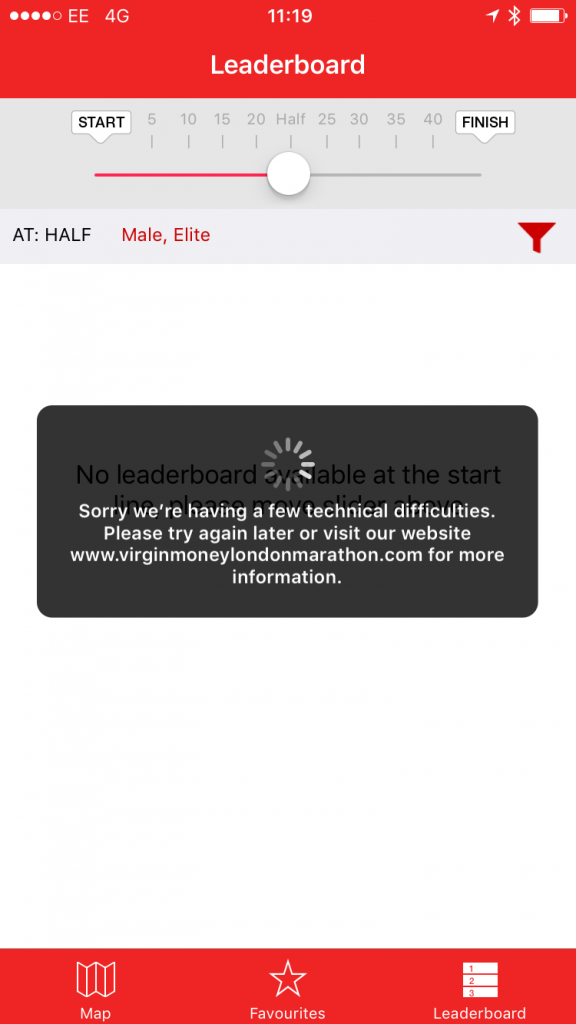
Frustrated Users
London Marathon Events Ltd. provided an open and honest response to the crash:
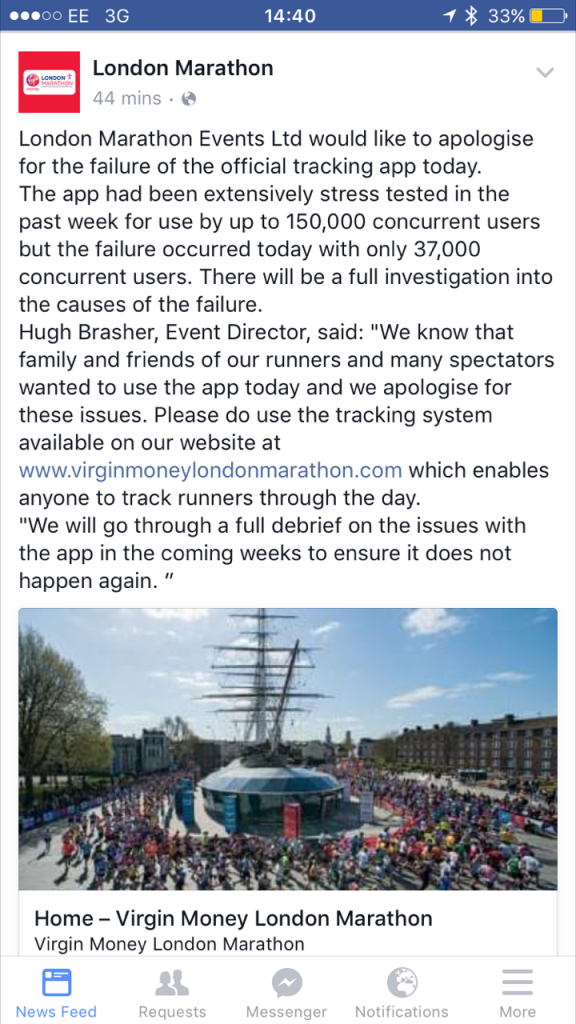
What went wrong and how to prevent this?
It appears that the goal of the app was to support 150,000 users. In defence of the organisers, this is a non-trivial task to achieve for the following reasons:
- 150,000 users is a significant target, even when compared to the Black Friday user volumes of very large UK online retailers
- This system lends itself to unavoidable peaks in demand, i.e. status updates of 38,000 runners every 5km and subsequent surge of requests from friends and family to view the updates
- The peaks occur over a short space in time, i.e. the average completion time of a runner is around 4 hours
- With the apps of large retailers, we can observe the system on a normal day and gain insight into how it will perform on a peak day. You can't do this here!
If the organisers tested the system to 150,000, then why did it crash? Well, we can only speculate based on our experiences elsewhere:

Were the test environments representative?
Was the hardware and software version tested, presumably some weeks ago, reflective of what was live on the day of the race?
Was there clear test success criteria?
It's key to have clear success criteria to judge is a load test passed or failed. This includes user counts, screen load time and screen throughput rates.
You can test to 150,000 users, but are you testing what the users are actually going to do?
You may have assumed that each user checks the leader board once per session, but this is not valid if they actually check 5-times per session. It will be key to use the data from this year to learn how the users accessed the app.
With high concurrency systems such as this, it is also important to understand how long idle users stay connected before their sessions are timed out.
It may not be possible to test every single IT component
Some of the IT components may not be able to be tested in a “laboratory” environment and so other approaches have to be followed. These could include Service Assurance where the service is tested in the production environment, typically during quiet periods; and Supply and Demand Modelling where observations in production and testing are combined to give an end-to-end view of the ability to meet business outcomes.
Conclusion
These crashes are high profile and cause great frustration, however planning and preventing them is non-trivial. On the plus side, there should be lots of data available to learn the lessons from this year!
If you would like to learn more about our Prepare for Peak and Performance testing solutions, please click below, to see our latest Ebook.


