Introduction
This whitepaper is designed for roles at all levels across enterprise IT involved in major change programmes (including digital transformation, re-platforming, cloud migration, datacentre migration) and following, or planning to adopt, agile and devops delivery models.
We cover the core principles and best practice approaches for ensuring good performance, whilst increasing the velocity of delivery.
Key Takeaways
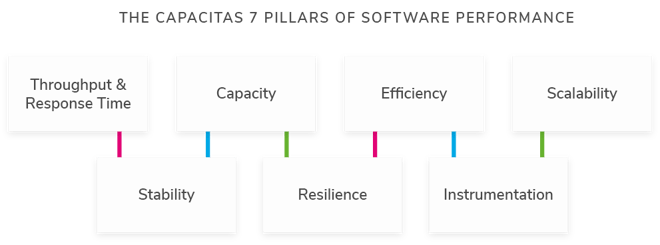
![]() Performance is not simply about response times and throughput. That is too simplistic a way to measure performance. An all-embracing approach to measuring performance is required. Capacitas’s 7 Pillars of Performance provide a comprehensive way of measuring performance.
Performance is not simply about response times and throughput. That is too simplistic a way to measure performance. An all-embracing approach to measuring performance is required. Capacitas’s 7 Pillars of Performance provide a comprehensive way of measuring performance.
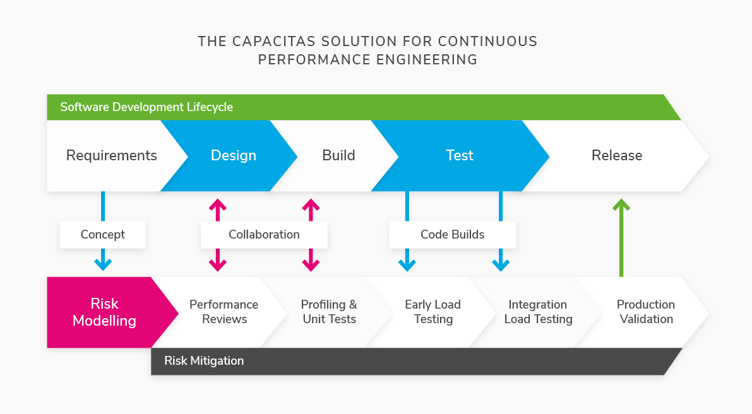
![]() In Agile & Continuous Cycles, there is simply not enough time to test every change. A risk based approach, using techniques such as Risk Modelling is required.
In Agile & Continuous Cycles, there is simply not enough time to test every change. A risk based approach, using techniques such as Risk Modelling is required.
![]() Shift Left & Continuous Collaboration. There needs to be a shift from performance engineers and analysts testing at the end to one where they are involved throughout the lifecycle and are collaborating with the developers to build a better understanding of the software and also refine the conceptual model of the platform.
Shift Left & Continuous Collaboration. There needs to be a shift from performance engineers and analysts testing at the end to one where they are involved throughout the lifecycle and are collaborating with the developers to build a better understanding of the software and also refine the conceptual model of the platform.
Smart Design: smart test designs are needed to expose risks at lower loads and in narrow test windows.
![]() Automation of Testing & Analysis. Automated analysis needs to address not just response times and throughput but all 7 Pillars of Performance.
Automation of Testing & Analysis. Automated analysis needs to address not just response times and throughput but all 7 Pillars of Performance.