How Can We Optimise AWS Costs?
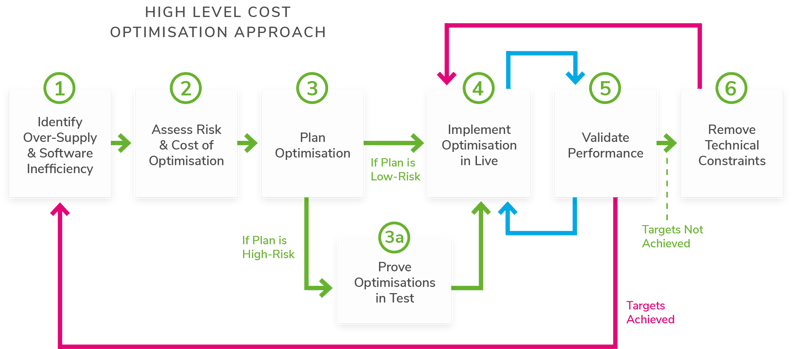
Our high-level process for achieving cost optimisation is shown in Figure 2. The solution below focuses on addressing the cost inefficiency challenges 1 – 4 which account for 70%+ of the cost optimisation opportunities in the cloud.
 Identify Over-Supply & Software Inefficiency
Identify Over-Supply & Software Inefficiency
The first step is a diagnostic to identify two symptoms of high cost: over-supply and software inefficiency.
Over-supply is when the capacity provisioned exceeds demand over the IT service’s demand cycle. The concept of over-supply may be applied to any AWS component.
For example, in the case of EC2 instances we would employ standard measures of CPU, memory and disk. For serverless components, such as Lambda, we would use time as a measure of resource consumption; this isn’t a precise measure of efficiency but can be a useful proxy.
Once over-supply is identified, we need to qualify that capacity can be reduced safely. When capacity is reduced, the performance of the application should not degrade and there should definitely be no service incidents. In order to make this assessment, we model the expected performance, post down-sizing using our Seven Pillars of Software Performance (below).

This enables us to quantify the performance risk associated with reducing supply capacity and thus prioritise which systems should be addressed.
Software efficiency is defined as the amount of compute resource required to process an application request or transaction, where compute resource includes processor, memory, disk space or I/O (network and disk). How do we decide whether software is efficient or inefficient? The business-function of the software will determine its compute requirements. For example we would expect e-commerce software to have a lower processing footprint (per request) than encryption software.
A big-data analytics platform will have a larger memory footprint (per request) than a document management service, and so on. As enterprise cloud environments typically have tens or hundreds of thousands of servers and components, we use automated software to harvest the following data:
- Cloud configuration
- Supply and utilisation data
- Demand data
- Cost data
Capacitas uses a library of software efficiency benchmarks, built up over hundreds of customer engagements, and dimensioned by software type, to assess whether the measured compute cost is efficient or not. This is likely to be more difficult for non-specialists whose experience of measuring efficiency Is limited to handful of systems.
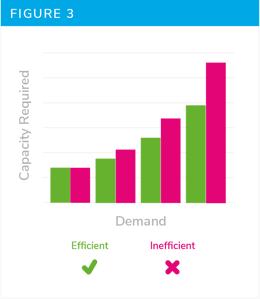
In order to get around that your organisation needs to build its own library of efficiency benchmarks; over a number of years it will become clearer what good looks like (Figure 3). Just remember to keep the older benchmarks up to date as technology changes.
Cloud cost monitoring tools such as Cloudability and Cloudyn provide great information on where there is over supply in the estate. However, they cannot identify software inefficiency as a driver of cloud capacity consumption.
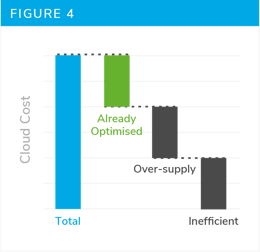
As an output from this phase we will have a list of the candidate systems which could be downsized and the potential cost reduction opportunity.
Identify Optimisations and Associated Risk & Cost
The next stage is to quantify how much optimisation we can realistically achieve, given the constraints. What should our $ cost optimisation target be?
The goals of this phase are:
- Define what right-sizing is required
- Define architectural optimisations
- Define what software efficiency improvements are required
- Define what configuration change is required to increase application elasticity
- Quantify the performance risk of changes [1-4]
- Quantify the $ cost optimisation that changes
[1-4] will achieve
Once we have quantified the performance risk of the changes, we can build a picture of what changes can be realistically delivered, without impacting the operation and reliability of production services (Figure 5).
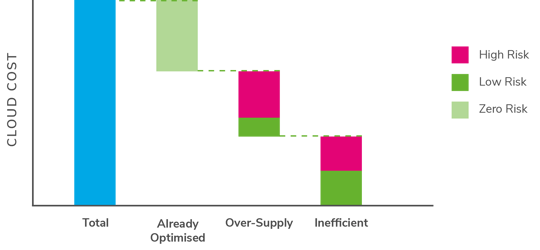
Cloud cost monitoring tools provide great information on about over supply in the estate. However, the key question remains: Can I safely reduce capacity without impacting the performance of the application? Unfortunately, these tools cannot inform this decision.
Plan Optimisation
In this phase we produce the detailed low-level designs for each type of optimisation:
- Right-sizing
- Architectural optimisations
- Software efficiency improvements
- Changes to increase application elasticity




 AWS autoscaling is
AWS autoscaling is 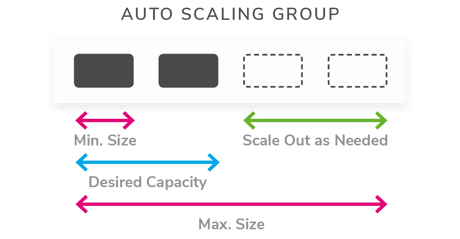
 Choosing a sub-optimal architecture for your workload will lead to higher cloud costs.
Choosing a sub-optimal architecture for your workload will lead to higher cloud costs.



